
信息与内容安全第一次实验
前言
由于本人学识尚浅,对于人工智能和机器学习这部分了解不多,故本实验单纯为复现性实验,并没有什么技术含量,可以看成一次简单的实验记录 :)
第一次实验是对前十次课程内容总结归纳之后的应用性实验,包括时下对抗机器学习最流行的FGSM算法实现和贴近实际场合的虚假人脸识别问题。本次实验工作环境全程在 Ubuntu22.04 和 PyTorch 2.0 下完成,涉及代码部分全部使用Python实现,兼以代码注释和实验结果文字说明。
对抗样本攻击实验
题目简述:根据PyTorch官网下的Adversarial Example Generation章节内容,完整实现FGSM算法对MNIST分类器的扰乱。
攻击原理
对于上下文,有许多类别的对抗性攻击,每个类别都有攻击者知识的不同目标和假设。然而,在一般来说,总体目标是增加最少的扰动到输入数据以导致所需的错误分类。有攻击者知识的几种假设,其中两种 分别是:白盒和黑盒。白盒攻击假定攻击者完全了解和访问模型,包括 架构、输入、输出和权重。黑盒攻击假设攻击者只能访问模型的输入和输出,并且对底层架构或权重一无所知。有还有几种类型的目标,包括错误分类和来源/目标错误分类。错误分类的目标意味着对手只希望输出分类错误,但确实如此,不在乎新的分类是什么。源/目标错误分类意味着对手想要更改最初属于特定的源类,因此它被归类为特定目标类。
在这种情况下,FGSM攻击是一种白盒攻击,目的是错误分类。其原理是攻击者调整输入数据来最大化拟合损失,攻击者会用到输入数据的损失梯主要步骤分为输入参数,定义模型,编写攻击代码,运行测试。
输入参数
本实验输入参数只有3个:
- 运行的 epsilon 值列表——定义对抗强度的等级
- 预训练的 MNIST 模型——本实验选择了已有的 example 模型
- Use_cuda 标志——本实验使用的是 CPU 版 PyTorch ,所以值的真假并不重要
攻击代码
#Define FGSM function
def fgsm_attack(image, epsilon, data_grad):
# Collect the element-wise sign of the data gradient
sign_data_grad = data_grad.sign()
# Create the perturbed image by adjusting each pixel of the input image
perturbed_image = image + epsilon*sign_data_grad
# Adding clipping to maintain [0,1] range
perturbed_image = torch.clamp(perturbed_image, 0, 1)
# Return the perturbed image
return perturbed_image
该函数读取三个输入,原始图像 x,像素级损失扰动 epsilon,以及输入图像损失的梯度data_grad.
然后通过测试函数计算梯度损失,创建扰动之后的图像,验证其对抗性,保存并返回对抗成功的样例。
最后一部分是实际运行攻击。
运行测试
得到如下结果:
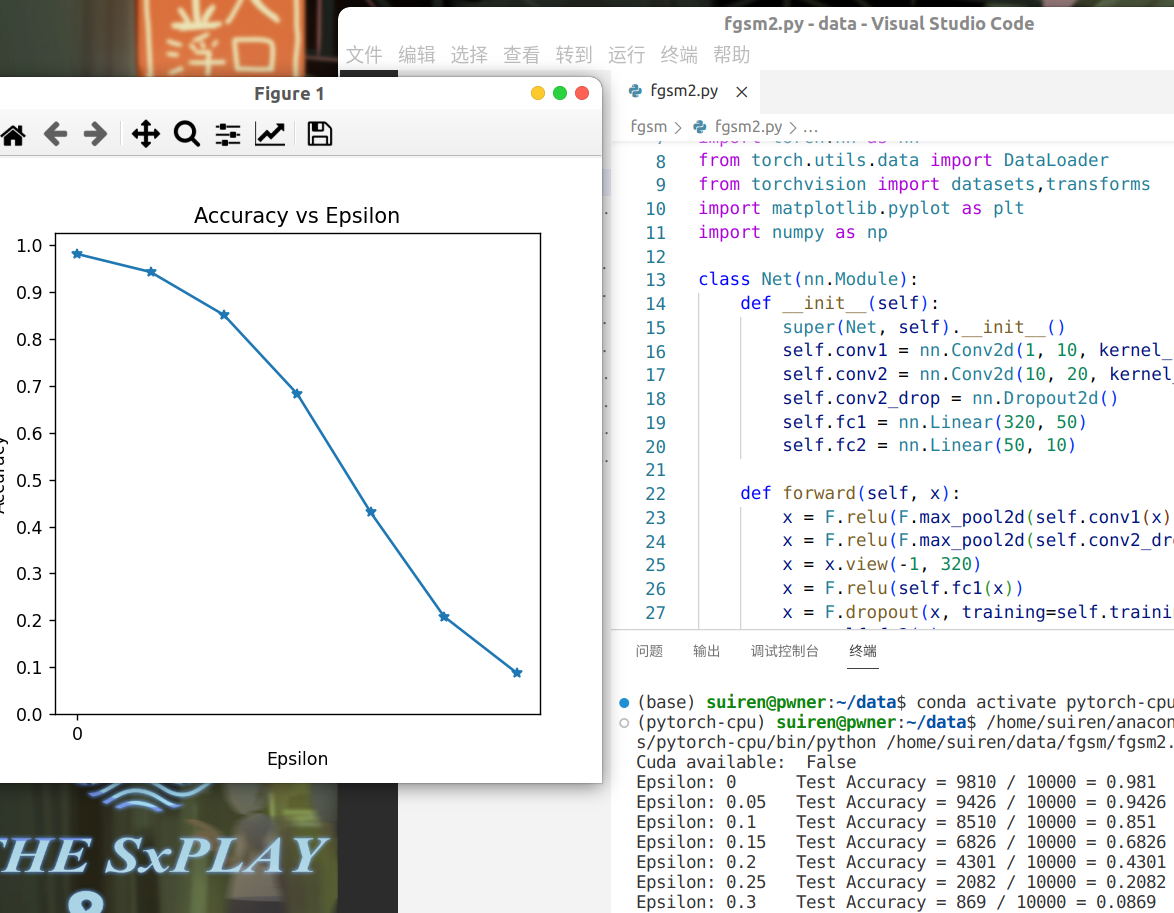
更直观的效果可见下面这张图,随着epsilon增大,识别准确度愈来愈低。
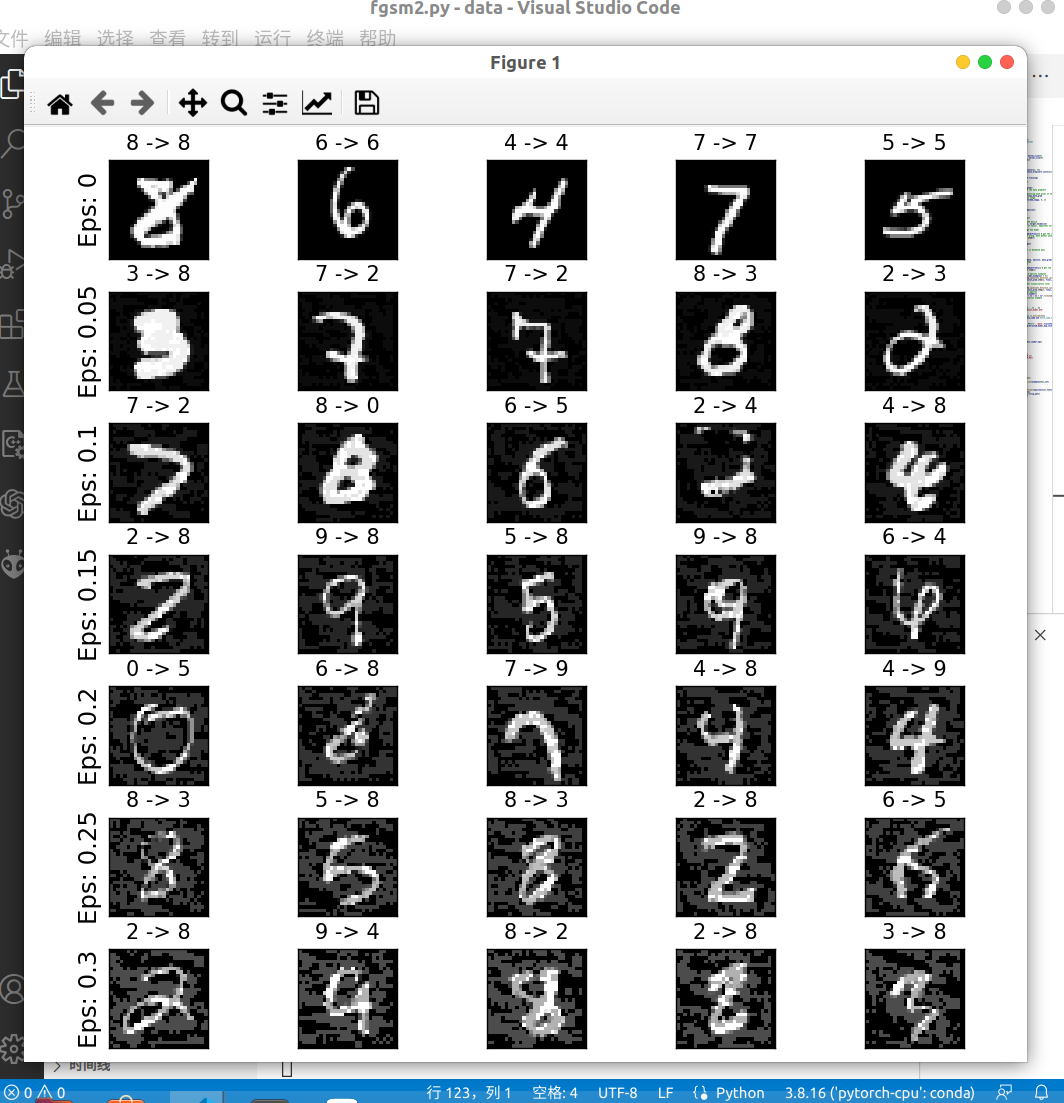
结果分析
可以看到,随着 epsilon 扰动量的增大,被攻击的模型区分精准度越来越低,而且在不设置扰动,也就是 epsilon=0 时,模型也不能做到100%准确。虽然 epsilon 值的增大使测试的精准度降低,但是扰动也变得更容易察觉了。这是就需要攻击者权衡攻击强度和被察觉的风险。将图片增加噪声后可以对机器学习产生扰动,但是依然很容易被人类区分——验证码、人机生物识别图像的模糊效果和作用正是基于这一点。
虚假人脸检测模型
这一部分主要参考了PyTorch官方教程的迁移学习章节,是对参考文献(6)的复现。本质是实现一个二分类器。其中心思想为:在大数据集上预训练ConvNet,然后使用ConvNet作为一个初始化或者固定功能提取器。
- ConvNet 作为固定特征提取器:在这里,我们将冻结权重对于所有网络,除了最终完全链接的网络层最后一个完全连接的层将替换为新层使用随机权重,只对该层进行训练。
- 微调ConvNet : 我们不是随机初始化,而是用预先训练好的网络初始化网络,比如在imagenet 1000数据集上接受训练。剩下的训练看起来也都一样。
分类结果演示


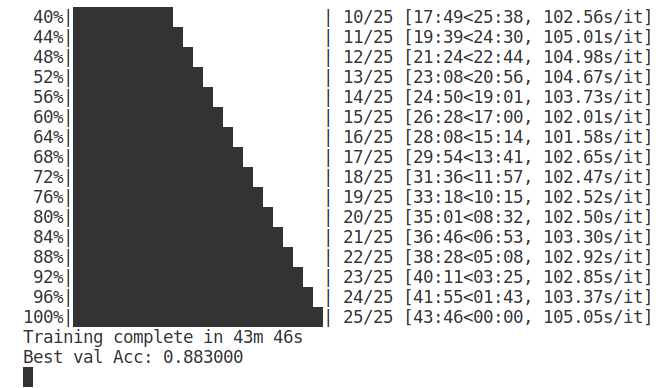
经过40多分钟的训练,模型的最高准确度达到了88.3%,这和一部分分类结果展示基本吻合。但是仍然不算高,接下来我们对网络进行微调,加载预训练的模型,并重置最终完全连接的层。
微调网络
model_ft = models.resnet18(pretrained=True)
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs, 2)
model_ft = model_ft.to(device)
criterion = nn.CrossEntropyLoss()
# Observe that all parameters are being optimized
optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9)
# Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)
model_ft = train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler,num_epochs=15)
PATH = ‘./fakeFace_ft_{}.pth’.format(model_ft.class.name)
torch.save(model_ft.state_dict(), PATH)
visualize_model(model_ft)
plt.ioff()
plt.show()
结果演示
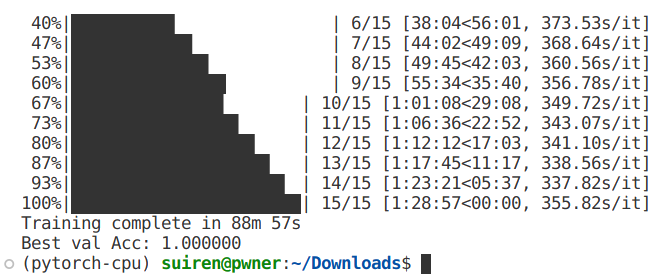
微调之后只有15轮epoch,但没想到这次训练的时间更长,经过漫长的90分钟后,模型终于训练完毕了。准确率更是达到了惊人的100%!


总结
第一次接触机器学习,确实非常陌生,有些问题及其消磨时间,折磨人的心态,治疗低血压,考验抗压能力。
在anaconda环境下有些模块会出现未解析的问题,需要 conda install 一下。
anaconda框架非常占用存储空间,最初分配的30G磁盘很快就用完了,中途有数次因为存储空间爆满导致实验无法继续,尽量在虚拟机安装时分配40G及以上空间。
内存空间和处理器内核可以尽量多分配,机器学习非常吃设备性能。参考文献中使用了GPU提高算力,极大加速了训练过程。但是实验要求的是CPU版,总的训练时间比较长。最后我给虚拟机分配了8G内存,总共使用了8核工作。
最开始我是打算自己实现 Xception,为此翻遍了 CSDN 和 Github ,最后仍收效甚微。决定还是参看学长的博客,使用预训练过的 ResNet18 .虽然初步分类效率不如 Xception ,但是在微调之后效果确实最好的。
AI确实是富哥们玩的游戏,没有一个精良以上的设备根本不足以支撑你的动作。目前我手上的 Y9000X 2022 搭载的 i7-12700 性能已经算比较强的了,仍然跑了很久的。听同学说他入学买的轻薄本,放在宿舍跑了7个小时;很难想象如果去年没有把小新换掉,半夜里会等到多绝望。
整个五一假期,大部分时间都用在这个实验上了,最后终于还是跑出了结果,结局总是好的 :)
参考文献
- https://www.jianshu.com/p/43f66c69baa7
- https://pytorch.org/tutorials/
- https://pytorch.org/tutorials/beginner/fgsm_tutorial.html
- https://blog.csdn.net/zywcj1314/article/details/108013129
- https://web.xidian.edu.cn/jcdu/files/60dc72cc6e0a8.pdf
- https://blog.csdn.net/weixin_47102975/article/details/124590857
- https://pytorch.org/tutorials/beginner/transfer_learning_tutorial.html